Large Vision Models: A Glimpse into the Future of Industry 5.0

Introduction
In the era of Industry 5.0, the convergence of Artificial Intelligence (AI) and the Internet of Things (IoT) is revolutionizing the manufacturing sector. One of the key technologies driving this transformation is Large Vision Language Models (LVL), which have the potential to reshape how industries operate and innovate. Imagine smart cameras analyzing visuals, identifying issues, and communicating findings in clear language. LVL models are poised to drive innovation across sectors like automated quality control, predictive maintenance, workplace safety, and real-time process monitoring. As industries embrace Industry 5.0 principles, adopting LVL models will accelerate, fostering human-machine collaboration. This blog post explores the impact of LVL models in computer vision and their role in shaping the future of Industry 5.0.
Understanding Industry 5.0 and Its Core Objectives: - Industry 5.0 marks a significant shift towards a new paradigm in the industrial revolution
characterized by the integration of advanced technologies such as AI, IoT, and automation with the human touch. This next evolution in industry goes beyond the digital transformation brought about by Industry 4.0, focusing on personalized production, sustainability, and enhancing human-machine interaction. At its heart, Industry 5.0 is not just about leveraging smart technologies to increase production efficiency but also about redefining the role of humans in the manufacturing process. The primary objectives of Industry 5.0 are multifaceted. Firstly, it aims to achieve a higher degree of customization in manufacturing, allowing for more personalized products to meet diverse consumer demands. This is a departure from the mass production models that have dominated previous industrial phases. Secondly, Industry 5.0 places a strong emphasis on sustainability, encouraging practices that minimize waste and environmental impact, aligning industrial processes with the global push towards green initiatives. Another key objective is the empowerment of the workforce through technology, ensuring that workers are not replaced but rather supported by automation and AI, leading to more meaningful and less hazardous jobs. These objectives underscore a holistic approach to industrial advancement, where technology serves not just economic goals but also societal and environmental needs. By fostering a synergistic relationship between human creativity and technological precision, Industry 5.0 aspires to create a more inclusive, sustainable, and efficient industrial landscape.
What are Large vision Models:-
Large vision models (LVMs) refer to advanced artificial intelligence (AI) models designed to process and interpret visual data, typically images or videos.These models are “large” in the sense that they have a significant number of parameters, often in the order of millions or even billions, allowing them to learn complex patterns in visual data. Large vision models train on large image dataset to recognize visual concept and images. Popular examples include Google's Imagen, and Stability AI's Diffusional can perform a variety of tasks such as image classification, object detection, image generation, and even complex image editing, by understanding and manipulating visual elements in a way that mimics human visual perception.
Examples of LVMs:-
- CLIP (Contrastive Language-Image Pretraining): Developed by OpenAI, CLIP is a vision-language model that's trained to understand images in conjunction with natural language. It can be used for tasks such as image captioning, visual question answering, and image retrieval. Here’s the paper: link
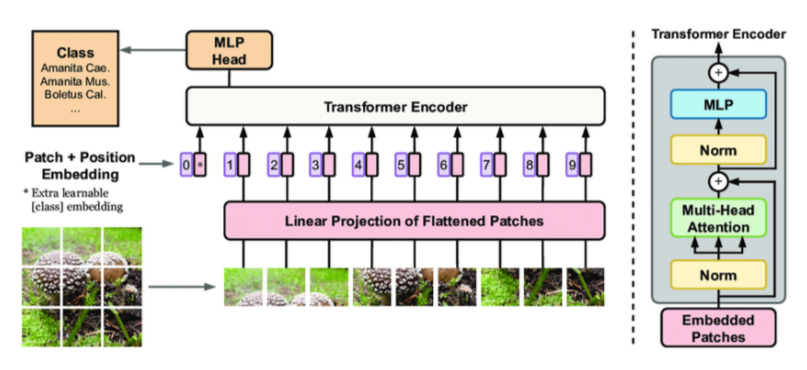
Google’s Vision Transformer (ViT): Also called ViT, this model is designed for image classification and employs a Transformer-like architecture over patches of the image. It has achieved state-of-the-art results on a variety of image classification benchmarks. Here’s the link to the paper: link
C LandingLens™: This is a platform developed by LandingAI that allows users to create custom computer vision projects without any prior coding experience. It provides an intuitive interface for labeling images, training models, and deploying them to the cloud or edge devices.
It breaks down images into different patches, processes them using transformers and aggregates the information which can be used for classification and object detection
ARCHITECTURE OF LVM ARE: -
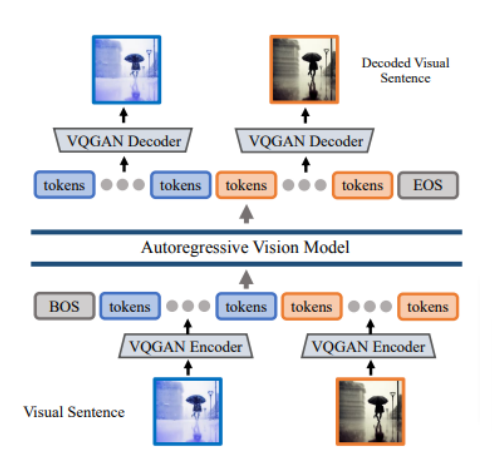
We follow two sage approaches for large vision language model are: - Image Tokenization: - The model uses a pre-trained VQGAN model to convert individual images into sequences of discrete tokens. VQGAN works by clustering image features into a codebook, allowing each image to be represented by a series of codes from the codebook. Essentially, it breaks down the image into a sequence of meaningful elements.
Auto regressive Transformer Model:
- The sequences of tokens from all images in a visual sentence (a series of images) are concatenated into a single 1D sequence.
- This sequence is fed into an autoregressive transformer model similar to those used in large language models. The model predicts the next token in the sequence based on the previous tokens.By training on this prediction task, the model learns the relationships between images within a visual sentence.
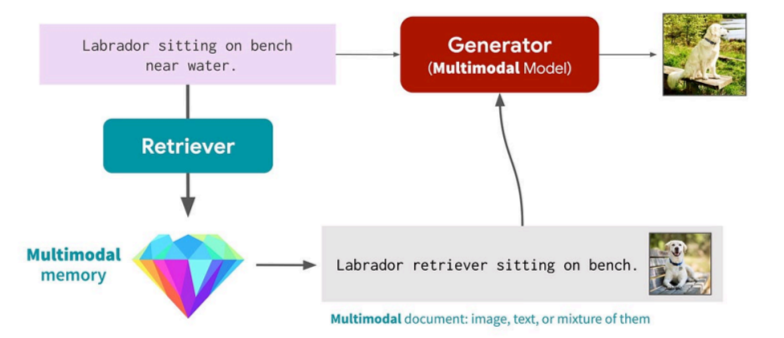
Multimodal RAG for Images and Text:
- Retriever:-It takes a query (text or images ) and compares it to documents stored in its “memory” (a large dataset of text and images).we use an encoder to map the query and the memory document into dense vectors–query vector and memory vector, respectively–, and then compute their cosine similarity as the relevance score.For the encoder, we use the pre-trained CLIP, which can map both text and an image into a shared vector space.
- Generator:-To incorporate the retrieved images and text into the generator, we prepend them to the main prompt x, and feed the resulting sequence (m1 , …, mK, x) into the Transformer and give the output.
Application of large vision models are:-
- Truck Analytics: - Large vision model helps in augmenting the dataset which can be used for training the model which helps classifying the truck plate detection and traffic motoring .
- Artificial Intelligence in Manufacturing: -VMs excel at identifying subtle visual anomalies in products. By analyzing images captured during production, they can detect defects like cracks, scratches, misprints, or improper assembly. This ensures consistent product quality and reduces the need for manual inspection, which can be slow and error-prone.
- PPE Safety - Large vision models can be used to detect workers are wearing gloves, helmet ,chemical-resistant clothing if they are not wearing it will generate alarm.
- Intrusion detection: - LVMs excel at real-time image recognition and processing. This allows for Identifying unauthorized individuals entering restricted areas, spotting tampering attempts with security cameras or sensors.
Addressing Challenges and Ethical Considerations:
The deployment of Large Vision Language Models (LVLs) in various industries, while promising, brings to the fore significant ethical and privacy concerns that cannot be overlooked. The capacity of these models to analyze vast amounts of visual data raises questions about the surveillance of individuals without their consent, potentially infringing on personal privacy rights. Furthermore, the issue of data security becomes paramount as these models process sensitive information that, if compromised, could lead to breaches with far-reaching consequences.
Another area of concern is the potential for algorithmic bias within LVL models. Given that these systems learn from data, any inherent bias in the training datasets can lead to skewed or unfair outcomes. This is particularly problematic in applications related to hiring, law enforcement, and surveillance, where biased decision-making can have serious implications for fairness and social justice.
To navigate these challenges, there is a pressing need for industries to adopt transparent and ethical AI practices. This involves the implementation of rigorous data governance policies to protect sensitive information and ensure compliance with data protection regulations. Additionally, efforts must be made to mitigate bias in AI systems, which includes diversifying training datasets and conducting regular audits of algorithmic decisions.
Engaging in open dialogues with stakeholders, including regulators, employees, and the wider public, about the ethical use of LVL models is also crucial. This will not only help in addressing concerns but also in building a foundation of trust and accountability as industries move forward in the era of Industry 5.0.
Looking Ahead: The Future of Computer Vision in Industry 5.0
With Industry 5.0 on the horizon, the fusion of Large Vision Language Models, AI, and IoT tech becomes essential. This powerful synergy is set to reshape industrial operations, creating more smart, flexible, and bespoke processes that match the modern market demands. Continual enhancements in LVL allow industries to boost efficiency and productivity while contributing to a safer and sustainable environment. The progress in computer vision technology represents a bright route to balance technology growth and ethical matters, assuring benefits not just for industry but also the society at large. By adopting these innovations, businesses can take the lead in developing intelligent, robust, and adaptable industrial ecosystems, ready for future challenges. The road ahead for computer vision in Industry 5.0 is laden with possibilities, forecasting a future where technological prowess and human innovation unite to bring unparalleled value.

Large Vision Models: A Glimpse into the Future of Industry 5.0